Learn initial preference → Learn context-dependent preferences → Adapt to preference shifts
Modern AI agents are powerful but often fail to align with the idiosyncratic, evolving preferences of individual users. Prior approaches typically rely on static datasets, either training implicit preference models on interaction history or encoding explicit user profiles in external memory. However, these approaches struggle with new users and with preferences that change over time.
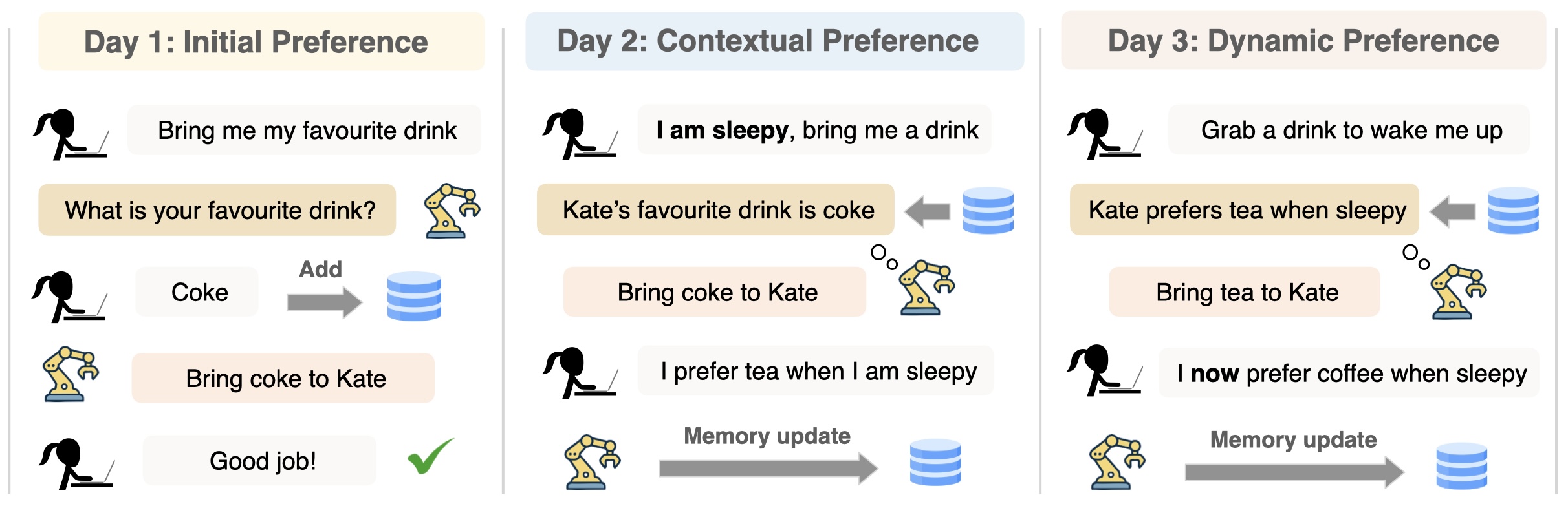
We introduce Personalized Agents from Human Feedback (PAHF), a framework for continual personalization in which agents learn online from live interaction using explicit per-user memory. PAHF operationalizes a three-step loop: (1) seeking pre-action clarification to resolve ambiguity, (2) grounding actions in preferences retrieved from memory, and (3) integrating post-action feedback to update memory when preferences drift.
We evaluate PAHF using a four-phase protocol across embodied manipulation and online shopping to measure initial learning and adaptation to preference drift. Theoretical and empirical results confirm that combining explicit memory with dual feedback is critical: PAHF consistently outperforms baselines, minimizing initial errors and enabling rapid recovery from non-stationary preferences.
Learn initial preference → Learn context-dependent preferences → Adapt to preference shifts
Explicit per-user memory with two feedback channels: pre-action clarification and post-action correction.
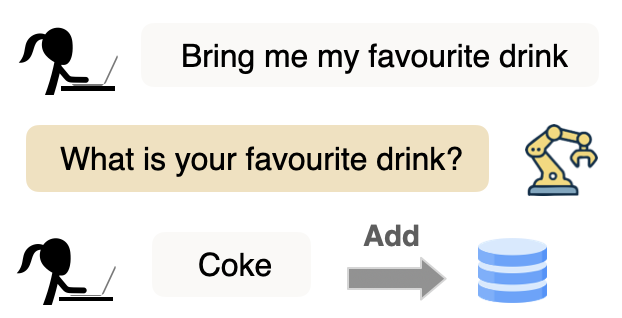
Pre-action Interaction
Ask if preference ambiguous
Action Execution
Act using retrieved memory

Post-action Correction
Use feedback to correct and refresh stale memory.

Our framework enables continual personalization by leveraging online user feedback to dynamically read and write to memory, ensuring the agent adapts to evolving preferences.

Embodied manipulation
Home/office tasks with contextual preferences.
Online shopping
Multi-constraint product selection.
Training
Phase 1
Initial Learning
Testing
Phase 2
Initial Personalization
Training
Phase 3
Adaptation to Drift
Testing
Phase 4
Adapted Personalization
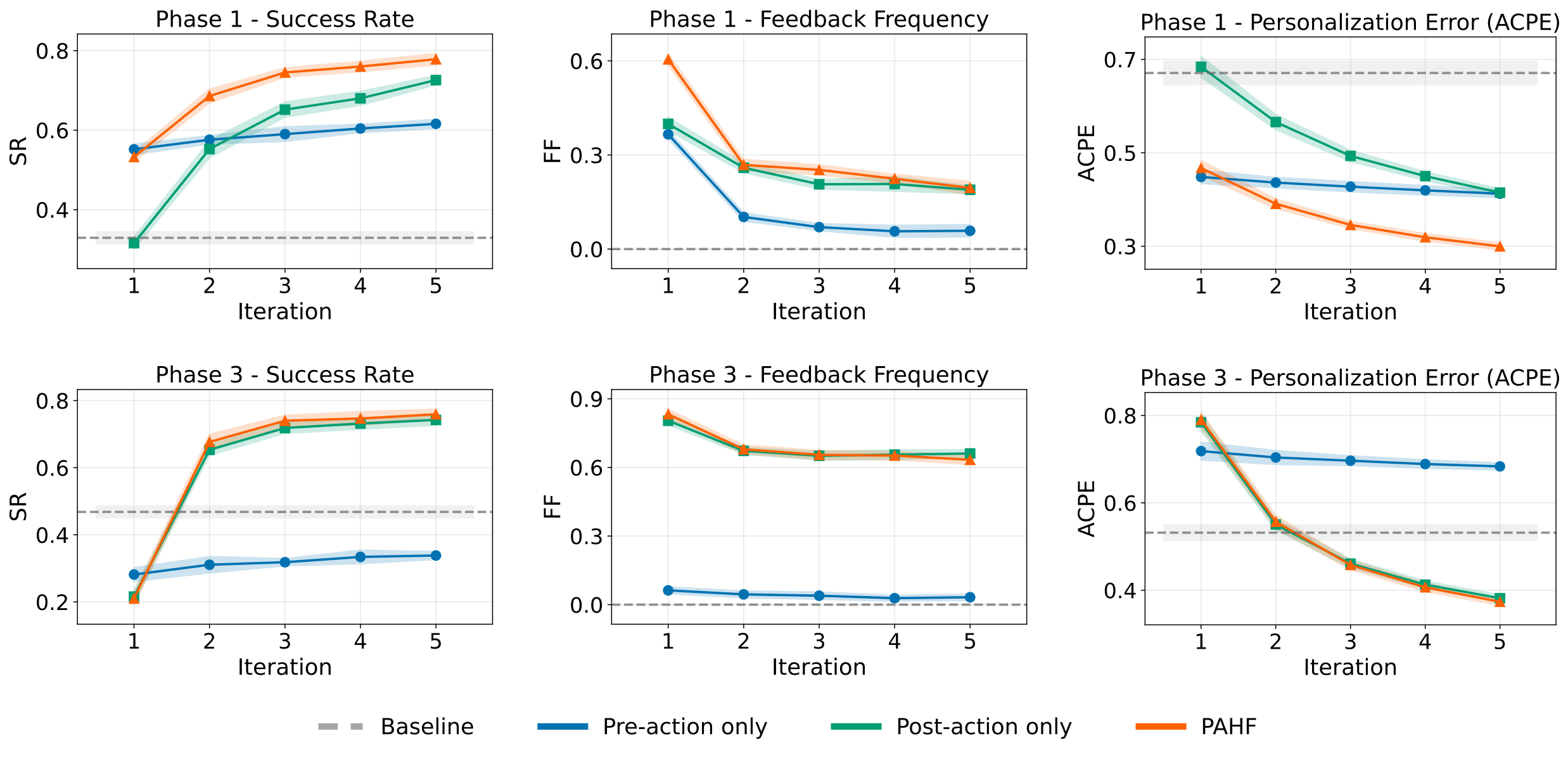
Learning curves for initial preference learning (Phase 1) and adaptation to preference shifts (Phase 3).
Test phase success rates
| Embodied | Shopping | |||
|---|---|---|---|---|
| Method | Phase 2 | Phase 4 | Phase 2 | Phase 4 |
| No memory | 32.3±0.4 | 44.8±0.5 | 27.8±0.2 | 27.0±0.4 |
| Pre-action only | 54.1±1.1 | 35.7±1.0 | 34.4±0.5 | 56.0±0.7 |
| Post-action only | 67.9±1.5 | 68.3±1.2 | 38.9±0.5 | 66.9±0.8 |
| PAHF (pre+post) | 70.5±1.7 | 68.8±1.3 | 41.3±0.8 | 70.3±1.1 |
@article{liang2026learning,
title={Learning Personalized Agents from Human Feedback},
author={Liang, Kaiqu and Kruk, Julia and Qian, Shengyi and Yang, Xianjun and Bi, Shengjie and Yao, Yuanshun and Nie, Shaoliang and Zhang, Mingyang and Liu, Lijuan and Fisac, Jaime Fern{\'a}ndez and others},
journal={arXiv preprint arXiv:2602.16173},
year={2026}
}